Feasibility Study – Can Language Models Learn Inflation Narratives In European Multi-Lingual Settings?
2026 03.19 16:37
研究者情報
Ryuichi Saito

Abstract
Evaluate the transfer capability from English to a middle resource language using representative language models for a multilingual economic study
Introduction
Motivation
Research motivation
In multilingual Europe, concerns about inflation, employment, and inequality differ across countries. Social media offers real-time signals of economic sentiment.
Research gap
Large-scale annotation for each language is impractical. It remains unclear whether encoder-based supervised fine-tuning (SFT) or Few-Shot (FS) / Zero-Shot (ZS) large language models (LLMs) are more label-efficient and reliable for multilingual NLP (Natural Language Processing).
 Figure1. Language of Europe (Wikipedia. 2025.)
Figure1. Language of Europe (Wikipedia. 2025.)
Objectives
Approach
This study compares SFT Multilingual Encoder and FS LLMs for cross-lingual transfer of English-labeled economic narratives to Swedish, Greek, and Hungarian across different label sizes.
Goal
To identify the most label-efficient and transferable model and setting for a multilingual framework.
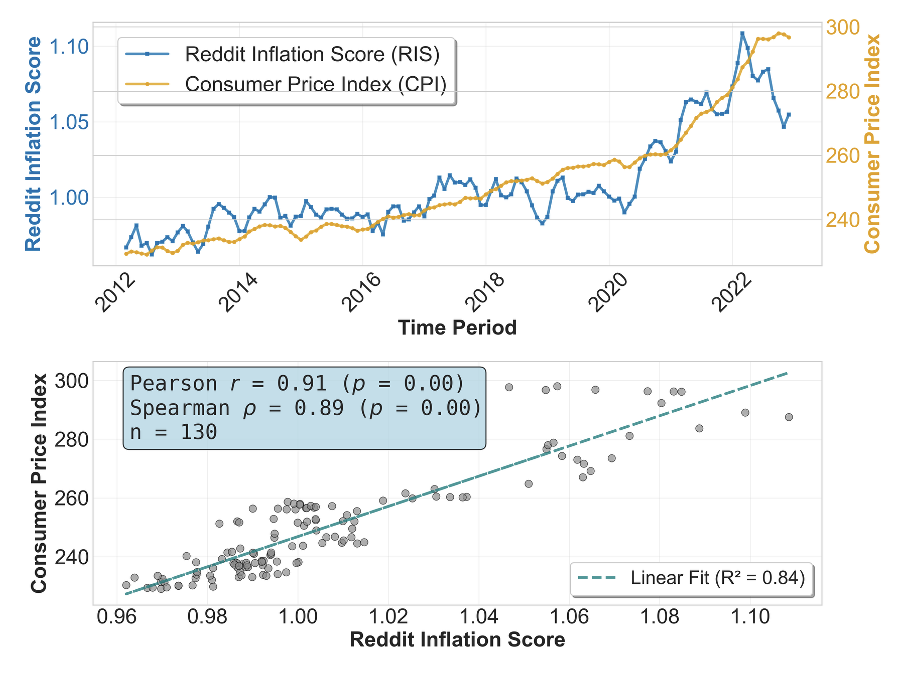 Figure 2. Example of the Reddit Inflation Score vs CPI in the U.S.
Figure 2. Example of the Reddit Inflation Score vs CPI in the U.S.
Proposed Methods
Experiment Setup
The feasibility of this study will be validated through the following steps
- Language Selection: Select representative languages while accounting for phylogenetic diversity. The focus will be on mid-resource languages with relatively fewer speakers, unlike French or German.
- Data Collection: Use the 2018 dataset for train/dev/test. In addition, prepare an English dataset with about 1,000 more samples to train the multilingual encoder. Datasets from 2019 to 2022 will be used as estimation targets, with each obtained through random sampling.
- Economic Sentiment Classification: As a baseline, use a multilingual encoder trained on the training data. As a low-cost approach that does not require training, use GPT-5.1.
Languages for Experiment
Representative languages selected for cross-lingual evaluation: English, Swedish, Greek, and Hungarian
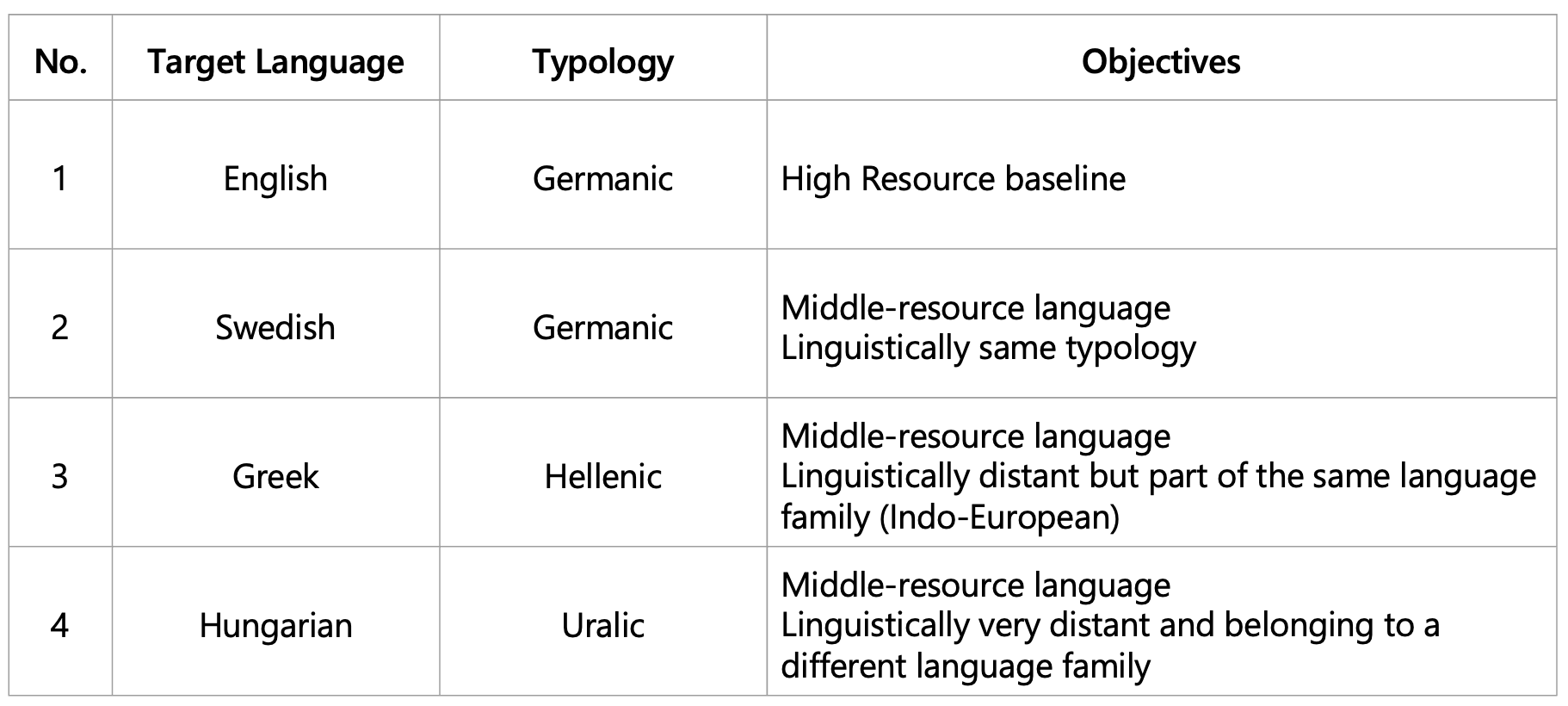 Table 1. Languages for Experiment
Table 1. Languages for Experiment
Data Collection
Reddit provides country-level, language-specific communities with sufficient time-series data
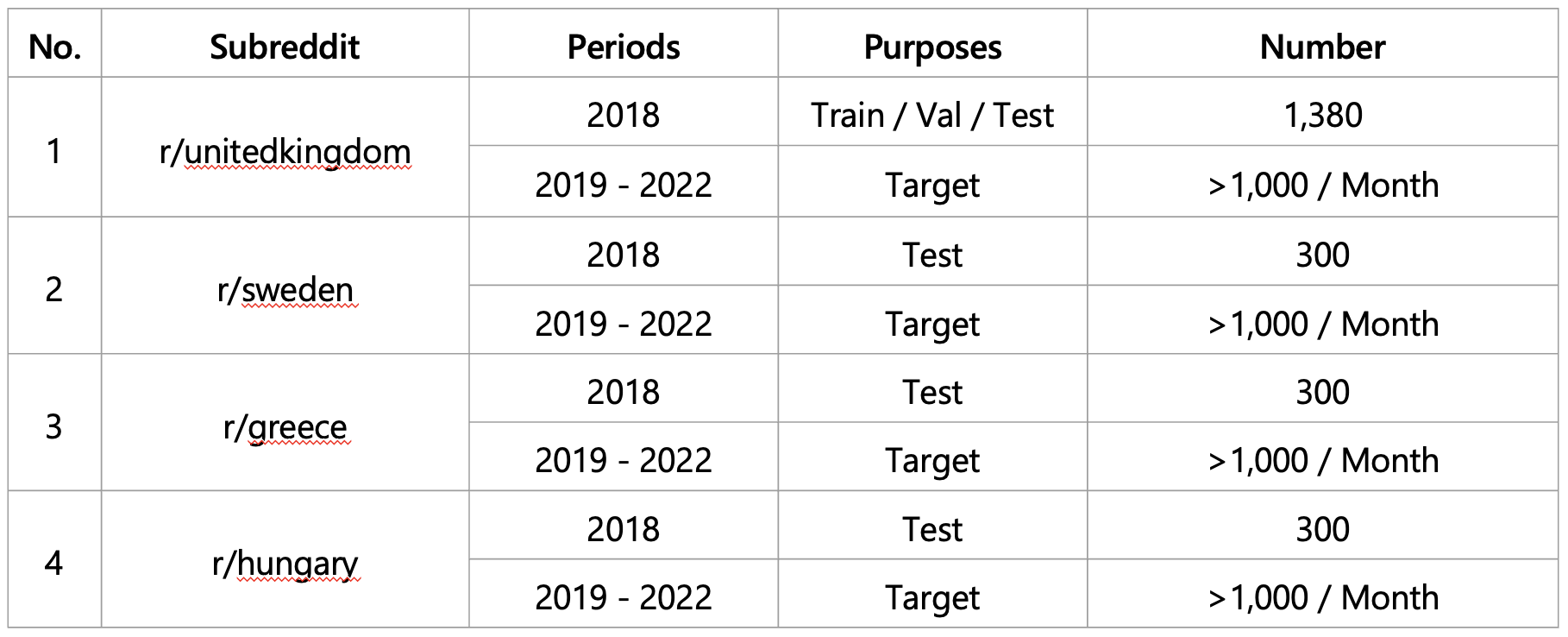 Table 2. Collection Data
Table 2. Collection Data
Economic Sentiment Classification Model
English-only setup enables multilingual classification without language-specific classifiers
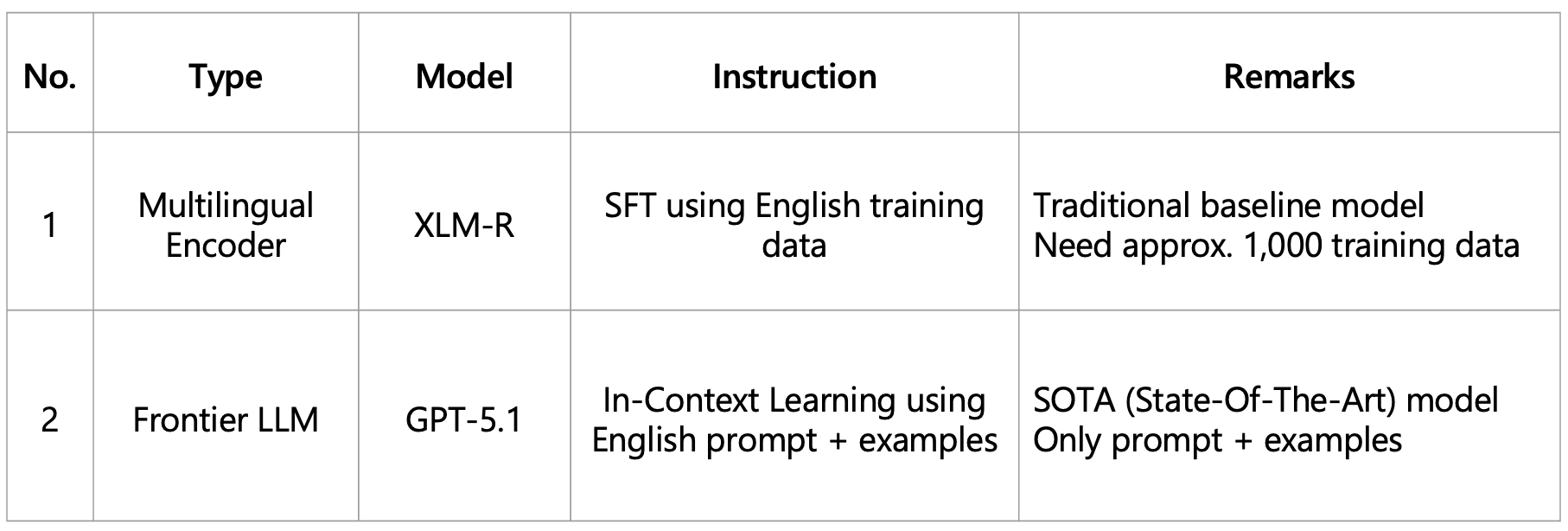
Table 3. Economic Sentiment Classification Model
Evaluation Result
Evaluation
- We test whether English-based training and in-context learning can transfer effectively to mid-resource languages.
- Macro-F1 is used as the main evaluation metric.
- For the multilingual encoder (XLM-R), we analyze performance under different English training-data sizes to examine its scaling behavior.
Result
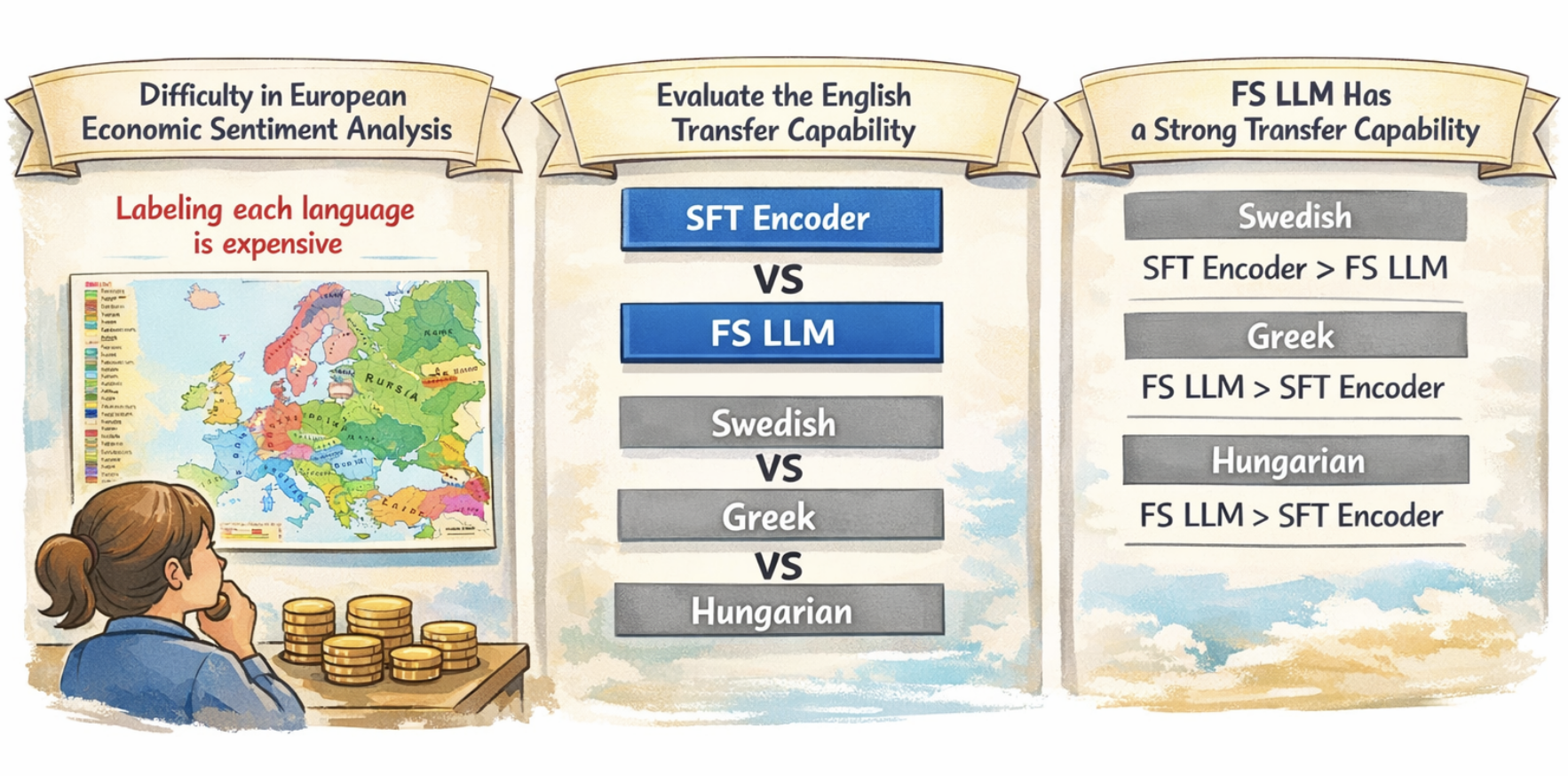
LLMs outperform multilingual encoders in Greek and Hungarian, while encoders remain competitive in English and Swedish
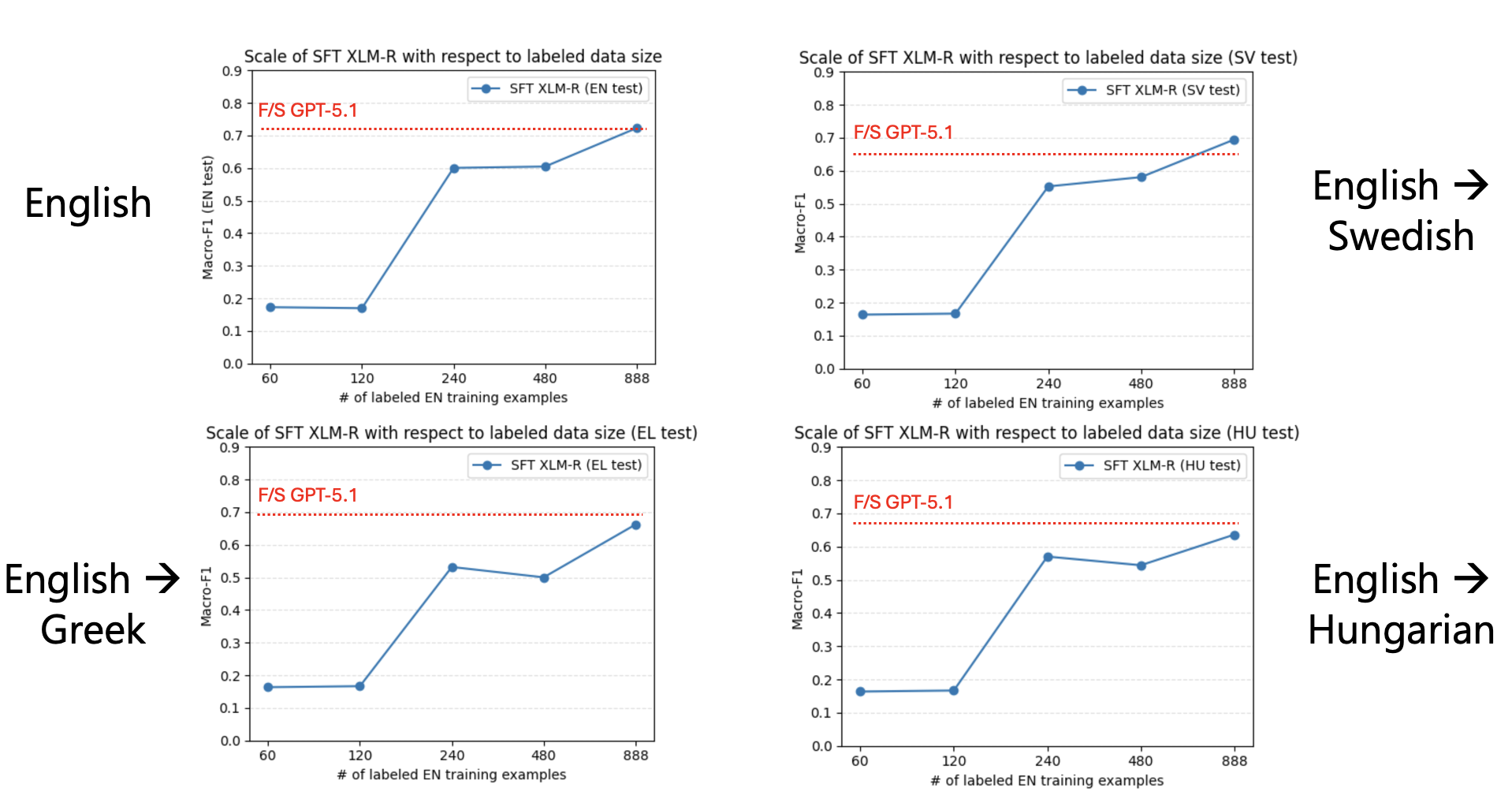 Figure 3. Evaluation Result for Each Language
Figure 3. Evaluation Result for Each Language
Takeaways
Data Availability: Confirmed that Reddit provides a sufficient volume of multilingual economic discussions (over 1,000/month) to serve as a viable data source for inflation analysis.
Performance Comparison: Initial results suggest that the performance of English SFT Encoders is comparable to that of FS Frontier LLMs in middle-resource language settings.
Editor’s Note
Initially, I planned to collect datasets from other social media platforms, but I encountered cost constraints. During this process, I discovered a newly released Reddit archive and realized that it would allow me to use even very recent post data. Although the deadlines for other conference papers were also approaching during this period and the resources I could allocate were limited, I was able to make steady progress.
In addition, because I was staying in Europe, I was able to attend ACL, one of the leading conferences in natural language processing (NLP). It was inspiring to see that my research topic fits within the scope of ACL, and also to witness firsthand the highly competitive environment led by many Chinese researchers.
*Visual image in the abstract was illustrated by ChatGPT 5.2 Thinking based on the slide objects.

References
| Saito, R., Tsugawa, S. (2026). Learning Inflation Narratives from Reddit: How Lightweight LLMs Reveal Forward-Looking Economic Signals. Proceedings of the International AAAI Conference on Web and Social Media. Accepted on March 15, 2026 |
Cases in the same field
-

Demonstration Research into the Effect of Facial Recognition Automatic Doors for Reducing the Workload of Nursery Staff
ServiceComparison2021/07/16
-

Investigation into Setting Hub Hierarchy From a Wide Area Perspective Focusing on Deviations From Reality
PlanComparisonVisualization2021/07/16
-

The Potential for Transformation of Activities Within a Vehicle Produced by Autonomous Driving – Focusing on Time Value when Traveling
TrafficComparisonCorrelation2021/07/16

